Introduction to the MVP Dataset
We present a novel large-scale dataset, Multi-grained Vehicle Parsing (MVP), for semantic analysis of vehicles in the wild, which has several featured properties.
-
The MVP contains 24,000 vehicle images captured in read-world surveillance scenes, which makes it more scalable for real applications.
-
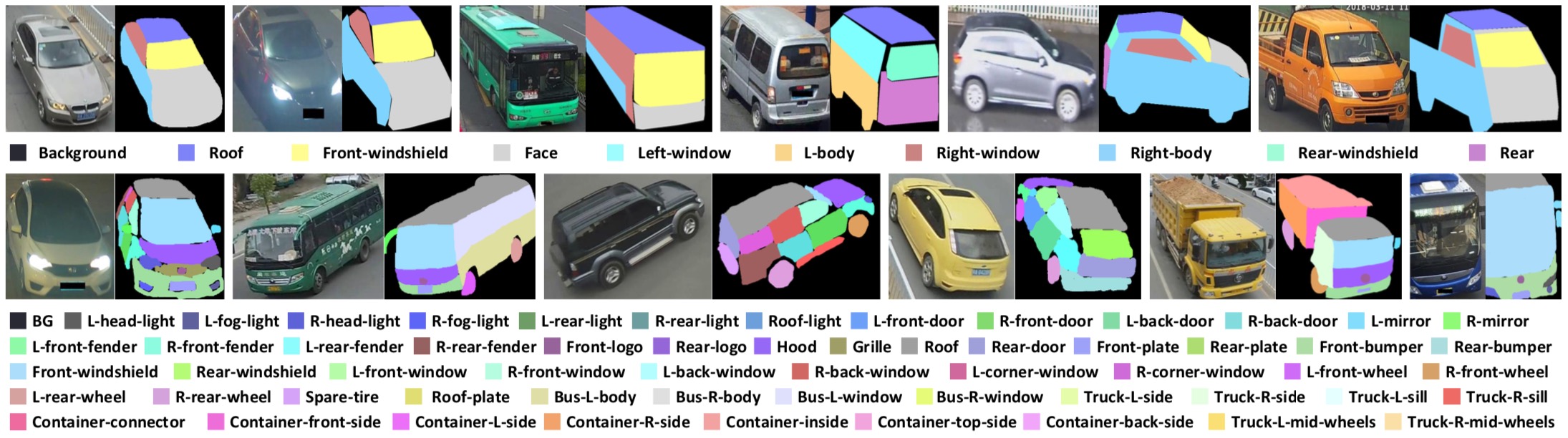
For different requirements, we annotate the vehicle images with pixel-level part masks in two granularities, i.e., the coarse annotations of ten classes and the fine annotations of 59 classes. The former can be applied to object-level applications such as vehicle Re-Id, fine-grained classification, and pose estimation, while the latter can be explored for high-quality image generation and content manipulation. The statistics of the dataset are as follows:
| Subset | Class Number | Image Number |
|---|---|---|
| MVP-coarse | 10 (9 parts + background) | 21000 |
| MVP-fine | 59 (58 parts + background) | 3000 |
- The images reflect complexity of real surveillance scenes, such as different viewpoints, illumination conditions, backgrounds, and etc. In addition, the vehicles have diverse countries, types, brands, models, and colors, which makes the dataset more diverse and challenging.
How to Get It
The vehicle images are sampled from three public datasets for vehicle re-identification, i.e., VeRi [1], AICITY19-ReID [2], and VeRi-Wild [3]. The original vehicle images should be obtained from the original owners of the three datasets.
The MVP dataset provides only the vehicle parsing annotation and can be downloaded from: Baidu Pan (download code: o7l2) or Google Drive. The code and vehicle parsing models trained on the MVP dataset can be directly used from this repo. The train/val/test splitting files used in our experiments can be found here.
If you use our dataset, please kindly cite our paper:
@inproceedings{liu2020pcrnet,
title={Beyond the Parts: Learning Multi-view Cross-part Correlation for Vehicle Re-identification},
author={Liu, Xinchen and Liu, Wu and Zheng, Jinkai and Yan, Chenggang and Mei, Tao},
booktitle={ACM International Conference on Multimedia},
year={2020}
}
Structure
The structure of the directory is organized as follows:
| SubDir | Description |
|---|---|
| coarse_annotation | coarse part annotation files |
| coarse_visualization_RGB | coarse part visualization files |
| fine_annotation | fine part annotation files |
| fine_visualization_RGB | fine part visualization files |
| legend | legend files for visualization |
| fine_index_list.txt | each line shows the [‘fine-grained annotation index’ ‘original dataset’ ‘original image name’] |
| coarse_index_list.txt | each line shows the [‘coarse-grained annotation index’ ‘original dataset’ ‘original image name’] |
Palette
Coarse Annotation
| Mask Index | Vehicle Parts | Palette RGB |
|---|---|---|
| 0 | background | [0, 0, 0] |
| 1 | Roof | [127, 127, 255] |
| 2 | Front-windshield | [255, 255, 127] |
| 3 | Face | [212, 212, 212] |
| 4 | Left-window | [127, 255, 255] |
| 5 | Left-body | [255, 212, 127] |
| 6 | Right-window | [212, 127, 127] |
| 7 | Right-body | [127, 212, 255] |
| 8 | Rear-windshield | [127, 255, 212] |
| 9 | Rear | [212, 127, 212] |
Fine Annotation
| Mask Index | Vehicle Parts | Palette RGB |
|---|---|---|
| 00 | background | [0, 0, 0] |
| 01 | left-head-light | [95, 95, 95] |
| 02 | left-fog-light | [95, 95, 159] |
| 03 | right-head-light | [95, 95, 223] |
| 04 | right-fog-light | [95, 95, 255] |
| 05 | left-rear-light | [95, 159, 95] |
| 06 | right-rear-light | [95, 159, 159] |
| 07 | roof-light | [95, 159, 223] |
| 08 | left-front-door | [95, 159, 255] |
| 09 | right-front-door | [95, 223, 95] |
| 10 | left-back-door | [95, 223, 159] |
| 11 | right-back-door | [95, 223, 223] |
| 12 | left-mirror | [95, 223, 255] |
| 13 | right-mirror | [95, 255, 95] |
| 14 | left-front-fender | [95, 255, 159] |
| 15 | right-front-fender | [95, 255, 223] |
| 16 | left-back-fender | [95, 255, 255] |
| 17 | right-back-fender | [159, 95, 95] |
| 18 | front-logo | [159, 95, 159] |
| 19 | rear-logo | [159, 95, 223] |
| 20 | hood | [159, 95, 255] |
| 21 | grill | [159, 159, 95] |
| 22 | roof | [159, 159, 159] |
| 23 | rear-door | [159, 159, 223] |
| 24 | front-plate | [159, 159, 255] |
| 25 | rear-plate | [159, 223, 95] |
| 26 | front-bumper | [159, 223, 159] |
| 27 | rear-bumper | [159, 223, 223] |
| 28 | front-windshield | [159, 223, 255] |
| 29 | rear-windshield | [159, 255, 95] |
| 30 | left-front-window | [159, 255, 159] |
| 31 | right-front-window | [159, 255, 223] |
| 32 | left-back-window | [159, 255, 255] |
| 33 | right-back-window | [223, 95, 95] |
| 34 | left-corner-window | [223, 95, 159] |
| 35 | right-corner-window | [223, 95, 223] |
| 36 | left-front-wheel | [223, 95, 255] |
| 37 | right-front-wheel | [223, 159, 95] |
| 38 | left-rear-wheel | [223, 159, 159] |
| 39 | right-rear-wheel | [223, 159, 223] |
| 40 | spare-tire | [223, 159, 255] |
| 41 | roof-plate | [223, 223, 95] |
| 42 | bus-left-body | [223, 223, 159] |
| 43 | bus-right-body | [223, 223, 223] |
| 44 | bus-left-window | [223, 223, 255] |
| 45 | bus-right-window | [223, 255, 95] |
| 46 | truck-left-face | [223, 255, 159] |
| 47 | truck-right-face | [223, 255, 223] |
| 48 | truck-left-sill | [223, 255, 255] |
| 49 | truck-right-sill | [255, 95, 95] |
| 50 | container-connector | [255, 95, 159] |
| 51 | container-front-side | [255, 95, 223] |
| 52 | container-left-side | [255, 95, 255] |
| 53 | container-right-side | [255, 159, 95] |
| 54 | container-inside | [255, 159, 159] |
| 55 | container-top-side | [255, 159, 223] |
| 56 | container-back-side | [255, 159, 255] |
| 57 | truck-left-mid-wheel | [255, 223, 95] |
| 58 | truck-right-mid-wheel | [255, 223, 159] |
Reference
[1] Xinchen Liu, Wu Liu, Tao Mei, Huadong Ma: PROVID: Progressive and Multimodal Vehicle Reidentification for Large-Scale Urban Surveillance. IEEE Trans. Multimedia 20(3): 645-658 (2018)
[2] Zheng Tang, Milind Naphade, Ming-Yu Liu, Xiaodong Yang, Stan Birchfield, Shuo Wang, Ratnesh Kumar, David C. Anastasiu, Jenq-Neng Hwang: CityFlow: A City-Scale Benchmark for Multi-Target Multi-Camera Vehicle Tracking and Re-Identification. CVPR 2019: 8797-8806
[3] Yihang Lou, Yan Bai, Jun Liu, Shiqi Wang, Lingyu Duan: VERI-Wild: A Large Dataset and a New Method for Vehicle Re-Identification in the Wild. CVPR 2019: 3235-3243
Acknowledgement
This dataset is built with the support of Prof. Chenggang Yan and his students at Hangzhou Dianzi University.
This dataset is named MVP with 24K images to pay tribute to the great basketball player Kobe Bryant.