
-
Xinchen Liu (刘鑫辰)
-
Email:
 or
or  *My previous email xinchenliu [at] bupt [dot] edu [dot] cn has been deprecated.
*My previous email xinchenliu [at] bupt [dot] edu [dot] cn has been deprecated. -
Github: lxc86739795
About Me
I am currently a Senior Researcher leading the Fundamental Video Intelligence Lab at JD Explore Academy led by Dr. Xiaodong He. My research interests include multimedia computing, computer vision, generative models for visual content, and their applications in retail. I was working closely with Prof. Wu Liu and Dr. Tao Mei in my early career. I received my Ph. D. degree from the Beijing Key Lab of Intelligent Telecommunication Software and Multimedia, Beijing University of Posts and Telecommunications in 2018, under the supervision of Prof. Huadong Ma. I received my B.S. degree from Northwest A&F University in 2011.
We are recruiting self-motivated interns in computer vision and multimedia. Please send your CV to my email if you are interested in the positions! :D
Recent News
- May, 2025, our HOIGen-1M dataset for human-object interaction video generation can now be accessed on Hugging Face! Welcome to use it!
- Feb, 2025, Two papers about multi-modal generation was accepted by CVPR 2025. Congratulations to our team and collaborators!
- February, 2025, our team obtained the 2024 Chinese Association for Artificial Intelligence Wu Wenjun Artificial Intelligence Science and Technology Award, Special Prize for Technology Progress Award (中国人工智能学会吴文俊人工智能科技奖,科技进步特等奖). Link.
- January, 2025, we are organizing The Special Session of Multi-modal Agents for Visual Analysis and Generation in conjunction with IEEE ICIP. Paper submission due is 22 Jan 2024. Welcome submissions! Website
- July, 2024, we are organizing The 5th International Workshop On Human-Centric Multimedia Analysis (HUMA) in conjunction with ACM Multimedia 2024. Paper submission due is 31 July 2024. Welcome submissions! Website. Two challenges, Multimodal Human Motion Capture and Multimodal Gait Recognition, are also open for participation!
- July, 2024, One paper on gait recognition with multi-modal representations was accepted by ACM Multimedia 2024. Congratulations to our team and collaborators!
- March, 2024, One paper on action segmentation using IoT signals was accepted by ACM ToMM (arXiv). Congratulations to our collaborators!
- Febrary, 2024, One paper on efficient human NeRF was accepted by CVPR 2024 (arXiv). Congratulations to our collaborators!
- October, 2023, we will host The 4th International Workshop On Human-Centric Multimedia Analysis (HUMA) in conjunction with ACM Multimedia 2023. Workshop Date: 2, November, 2023 in Ottawa, Canada.
- September, 2023, our open-source toolbox FastReID (GitHub) was accepted by the open-source software competition session of ACM Multimedia 2023. Congratulations to our team and collaborators! FastReID is a PyTorch-based toolbox for general object re-identification with SOTA algorithms and models.
- August, 2023, One paper on gait recognition with a new dataset (Project) was accepted by ACM Multimedia 2023. Congratulations to our team and collaborators!
- June, 2023, we are organizing The 4th International Workshop On Human-Centric Multimedia Analysis (HUMA) in conjunction with ACM Multimedia 2023. Paper submission due is 31 July 2023. Welcome submissions! Website
- November, 2022, our paper “PROVID: Progressive and Multimodal Vehicle Reidentification for Large-Scale Urban Surveillance” was recognized as the ESI Highly Cited Paper (Top 1% of papers in the academic field).
- October, 2022, we are organizing a Special Issue of Human-centric Multimedia Analysis in the Journal of Multimedia Tools and Applications. Welcome submissions! Submission deadline: March 13, 2023. Final notification date: August 2, 2023. CALL FOR PAPER
- August, 2022, I gave the talk, “Gait Recognition from 2D to 3D”, at CCIG 2022 Young Scholar Panel (2022中国图象图形学大会,青年学者论坛). Thanks for the invitation of the committee. The slides can be downloaded here.
- June, 2022, we are organizing The 3rd International Workshop On Human-Centric Multimedia Analysis (HUMA) in conjunction with ACM Multimedia 2022. Paper submission due is 17 July 2021. Welcome submissions! Website
- June, 2022, four papers was accepted by ACM Multimedia 2022. The papers and codes will be available soon. Congratulations to our team and collaborators!
- June, 2022, our paper, “Part-level Action Parsing via a Pose-guided Coarse-to-Fine Framework”, on IEEE ISCAS 2022 was selected as IEEE CAS MSA-TC Best Paper Award - Honorable Mention. This is the second time our team has obtained this honor. Thanks to our collaborators!
- June, 2022, we are organizing The 3rd International Workshop On Human-Centric Multimedia Analysis (HUMA) with ACM Multimedia 2022. Paper submission due 10 August 2022. Website
- March, 2022, the Gait3D dataset and the code in our CVPR 2022 paper are now released! Any research can obtain the dataset by signing an agreement.
- March, 2022, we are organizing The 1st International Workshop on 3D Multimedia Analytics, Search and Generation (3DMM) in conjunction with IEEE ICME 2022. Paper submission due is extended to 27 March 2022. Welcome submissions! Website
- March, 2022, one paper on 3D gait recognition and a new benchmark Gait3D was accepted by CVPR 2022. Congrats to my intern Jinkai Zheng and thanks to our collaborators! The paper and the new dataset will be released soon.
- February, 2022, 40+ algorithms of CV, NLP, Supply Chain, etc. developed by our group and collaborators have been open-sourced on OpenI(启智). Welcome to use the codes at JD on OpenI.
- January, 2022, one paper on fine-grained action parsing was accepted as a lecture (oral) presentation by IEEE ISCAS 2022. Congratulations to my intern Xiaodong Chen and thanks to our collaborators!
- November, 2021, I will serve as an Area Chair for ICME 2022.
- October, 2021, our team obtained the 2nd Award in ICCV21 DeeperAction Challenge Track 3 - Kinetics-TPS Challenge on Part-level Action Parsing. Congratulations to our teammates Xiaodong Chen and Kun Liu! The technical report of our solution can be found HERE.
- September, 2021, The 2nd International Workshop On Human-Centric Multimedia Analysis (HUMA) will be held on 20 October 2021 in conjunction with ACM Multimedia 2021. This year we have three invited talks and five paper presentations. More details can be found on the Website.
- August, 2021, we are organizing The 2nd International Workshop On Human-Centric Multimedia Analysis (HUMA) in conjunction with ACM Multimedia 2021. Paper submission due is extended to 17 August 2021. Welcome submissions! Website
- July, 2021, one paper on Explanable Person ReID was accepted by ICCV 2021. Congrats to my intern Xiaodong Chen.
- May, 2021, our paper on IEEE ISCAS 2021 was selected as MSA-TC “Best Paper Award - Honorable Mention”. Thanks to our collaborators!
- May, 2021, our team is organizing ACM Multimedia Asia 2021. Paper submission due: 19 July 2021. Website
- April, 2021, we are organizing The 2nd International Workshop On Human-Centric Multimedia Analysis (HUMA) with ACM Multimedia 2021. Paper submission due: 10 August 2021. Website
- January, 2021, one paper on gait recognition was accepted as a lecture (oral) presentation by IEEE ISCAS 2021. Congratulations to Jinkai Zheng and thanks to our collaborators!
- December, 2020, our team won the Championship in NAIC Challenge 2020 AI+Person ReID Track. Congratulations to our teammates Xingyu Liao, Lingxiao He, Peng Cheng, and Guanan Wang!
- November, 2020, the codebase for human parsing and vehicle parsing in our papers of ACM MM’19 and ACM MM’20, has been released, please refer to CODE. It supported multiple segmentation and parsing methods and two datasets (LIP for humans, MVP for vehicles).
- November, 2020, the code for the paper, “Beyond the Parts: Learning Multi-view Cross-part Correlation for Vehicle Re-identification, ACM MM, 2020”, has been released, please refer to CODE.
- August, 2020, one regular paper and one demo paper are accepted by ACM Multimedia, 2020.
- July, 2020, we released a large-scale multi-grained vehicle parsing dataset, MVP dataset, for vehicle part segmentation. For more details, please refer to MVP.
- July, 2020, one paper was published on IEEE Transactions on Image Processing LINK.
- June, 2020, our team presented FastReID, a powerful toolbox of object re-identification for academia and industry. It achieves state-of-the-art performance for both person Re-Id and vehicle Re-Id. Please refer to our PAPER and CODE for more details.
- December, 2019, we made a performance list of recent vehicle Re-Id methods on the VeRi dataset. We also apply a strong baseline model for Re-Id on six vehicle Re-Id datasets. Please refer to LINK and the strong baseline model CODE.
- November, 2019, my Ph. D. Thesis, “Research on Key Techniques of Vehicle Search in Urban Video Surveillance Networks”, was awarded the Outstanding Doctoral Dissertation Award of China Society of Image and Graphics (中国图象图形学学会优秀博士学位论文). NEWS PDF
- October 22, 2019, one paper (Paper ID: P1C-10) will be presented at ACM Multimedia 2019, Nice, France.
- July, 2019, our paper, “PROVID: Progressive and Multimodal Vehicle Reidentification for Large-Scale Urban Surveillance” on IEEE Trans. Multimedia 20(3): 645-658, (2018), was awarded the TMM Multimedia Prize Paper Award 2019. Thanks to Dr. Wu Liu, Dr. Tao Mei, and Prof. Huadong Ma!
- July, 2019, one paper was presented at ICME 2019, Shanghai, China.
- June, 2019, one paper was presented at CVPR 2019, Long Beach, USA.
Publications (dblp Google Scholar)
2025
-
Kun Liu, Qi Liu, Xinchen Liu, Jie Li, Yongdong Zhang, Jiebo Luo, Xiaodong He, Wu Liu: HOIGen-1M: A Large-scale Dataset for Human-Object Interaction Video Generation. CVPR 2025. ARXIV Project Huggingface
-
Lifu Wang, Daqing Liu, Xinchen Liu, Xiaodong He: Scaling Down Text Encoders of Text-to-Image Diffusion Models. CVPR 2025. ARXIV
2024
-
Jinkai Zheng, Xinchen Liu, Boyue Zhang, Chenggang Yan, Jiyong Zhang, Wu Liu, Yongdong Zhang: It Takes Two: Accurate Gait Recognition in the Wild via Cross-granularity Alignment. ACM Multimedia 2024, 8786-8794. ARXIV
-
Xiaodong Chen, Kunlang He, Wu Liu, Xinchen Liu, Zheng-Jun Zha, Tao Mei: CLaM: An Open-Source Library for Performance Evaluation of Text-driven Human Motion Generation. ACM Multimedia 2024, 11194-11197. Paper
-
Hengyuan Liu, Xiaodong Chen, Xinchen Liu, Xiaoyan Gu, Wu Liu: AnimateAnywhere: Context-Controllable Human Video Generation with ID-Consistent One-shot Learning, ACM Multimedia 2024 HCMA Workshop. Paper
-
Caoyuan Ma, Yu-Lun Liu, Zhixiang Wang, Wu Liu, Xinchen Liu, Zheng Wang: HumanNeRF-SE: A Simple yet Effective Approach to Animate HumanNeRF with Diverse Poses. CVPR 2024. Paper
-
Qi Liu, Xinchen Liu, Kun Liu, Xiaoyan Gu, Wu Liu: SigFormer: Sparse Signal-Guided Transformer for Multi-Modal Human Action Segmentation. ACM ToMM 2024. Paper
2023
-
Jinkai Zheng, Xinchen Liu, Shuai Wang, Lihao Wang, Chenggang Yan, Wu Liu: Parsing is All You Need for Accurate Gait Recognition in the Wild. ACM Multimedia 2023, 116-124. (Oral Presentation) PROJECT ARXIV
-
Lingxiao He, Xingyu Liao, Wu Liu, Xinchen Liu, Peng Cheng, Tao Mei: FastReID: A Pytorch Toolbox for General Instance Re-identification. ACM Multimedia 2023, 9664-9667. GitHub ARXIV
-
Jingkuan Song, Wu Liu, Xinchen Liu, Dingwen Zhang, Chaowei Fang, Hongyuan Zhu, Wenbing Huang, John Smith, Xin Wang _HCMA’23: 4th International Workshop on Human-Centric Multimedia Analysis. ACM Multimedia 2023, 9734-9735.
2022
-
Guang Yang, Wu Liu, Xinchen Liu, Xiaoyan Gu, Juan Cao, Jintao Li: Delving into the Frequency: Temporally Consistent Human Motion Transfer in the Fourier Space. ACM Multimedia 2022, 1156-1166.
-
Xiaodong Chen, Wu Liu, Xinchen Liu, Yongdong Zhang, Jungong Han, Tao Mei: MAPLE: Masked Pseudo-Labeling autoEncoder for Semi-supervised Point Cloud Action Recognition. ACM Multimedia 2022, 708-718. (Oral Presentation)
-
Quanwei Yang, Xinchen Liu, Wu Liu, Hongtao Xie, Xiaoyan Gu, Lingyun Yu, Yongdong Zhang: REMOT: A Region-to-Whole Framework for Realistic Human Motion Transfer. ACM Multimedia 2022, 1128-1137.
-
Jinkai Zheng, Xinchen Liu, Xiaoyan Gu, Yaoqi Sun, Chuang Gan, Jiyong Zhang, Wu Liu, Chenggang Yan: Gait Recognition in the Wild with Multi-hop Temporal Switch. ACM Multimedia 2022, 6136-6145 ARXIV
-
Xiaodong Chen, Xinchen Liu, Kun Liu, Wu Liu, Dong Wu, Yongdong Zhang, Tao Mei: Part-level Action Parsing via a Pose-guided Coarse-to-Fine Framework. ISCAS 2022, 419-423 (Lecture Presentation) PAPER (IEEE CAS MSA-TC 2022 Best Paper Award Honorable Mention)
-
Jinkai Zheng, Xinchen Liu, Wu Liu, Lingxiao He, Chenggang Yan, Tao Mei: Gait Recognition in the Wild with Dense 3D Representations and A Benchmark. CVPR 2022, 20228-20237. PROJECT CODE ARXIV
2021
- Wu Liu, Xinchen Liu, Jingkuan Song, Dingwen Zhang, Wenbing Huang, Junbo Guo, John Smith: HUMA’21: 2nd International Workshop on Human-centric Multimedia Analysis. ACM Multimedia 2021: 5690-5691
- Xiaodong Chen, Xinchen Liu, Kun Liu, Wu Liu, Tao Mei: A Baseline Framework for Part-level Action Parsing and Action Recognition. CoRR abs/2110.03368 (2021) arXiv (2nd place solution to Kinetics-TPS Track on Part-level Action Parsing in ICCV DeeperAction Challenge 2021)
- Xiaodong Chen, Xinchen Liu, Wu Liu, Yongdong Zhang, Xiao-Ping Zhang, Tao Mei: Explainable Person Re-Identification with Attribute-guided Metric Distillation. ICCV 2021 PAPER PDF
- Jinkai Zheng, Xinchen Liu, Chenggang Yan, Jiyong Zhang, Wu Liu, Xiaoping Zhang, Tao Mei: TraND: Transferable Neighborhood Discovery for Unsupervised Cross-domain Gait Recognition. ISCAS 2021 PAPER PDF CODE (IEEE CAS MSA-TC 2021 Best Paper Award Honorable Mention)
2020
-
Xinchen Liu, Wu Liu, Jinkai Zheng, Chenggang Yan, Tao Mei: Beyond the Parts: Learning Multi-view Cross-part Correlation for Vehicle Re-identification. ACM MM 2020: 907-915 PDF CODE
-
Xiaodong Chen, Wu Liu, Xinchen Liu, Yongdong Zhang, Tao Mei: A Cross-modality and Progressive Person Search System. ACM MM Demo 2020: 4550-4552 PDF
-
Lingxiao He, Xingyu Liao, Wu Liu, Xinchen Liu, Peng Cheng, Tao Mei: FastReID: A Pytorch Toolbox for General Instance Re-identification. CoRR abs/2006.02631 (2020) ARXIV
-
Qi Wang, Xinchen Liu, Wu Liu, Anan Liu, Wenyin Liu, Tao Mei: MetaSearch: Incremental Product Search via Deep Meta-learning. IEEE Trans. Image Process. 29: 7549-7564 (2020) LINK
2019
-
Xinchen Liu, Meng Zhang, Wu Liu, Jingkuan Song, Tao Mei: BraidNet: Braiding Semantics and Details for Accurate Human Parsing. ACM MM 2019: 338-346 PDF
-
Xinchen Liu, Wu Liu, Meng Zhang, Jingwen Chen, Lianli Gao, Chenggang Yan, Tao Mei: Social Relation Recognition from Videos via Multi-scale Spatial-Temporal Reasoning. CVPR 2019: 3566-3574 PDF CODE
-
Xinchen Liu, Wu Liu, Huadong Ma, Shuangqun Li: PVSS: A Progressive Vehicle Search System for Video Surveillance Networks. J. Comput. Sci. Technol. 34(3): 634-644 (2019) PDF
-
Meng Zhang, Xinchen Liu, Wu Liu, Anfu Zhou, Huadong Ma, Tao Mei: Multi-Granularity Reasoning for Social Relation Recognition from Images. ICME 2019: 1618-1623 PDF CODE
2018
-
Xinchen Liu, Wu Liu, Tao Mei, Huadong Ma: PROVID: Progressive and Multimodal Vehicle Reidentification for Large-Scale Urban Surveillance. IEEE Trans. Multimedia 20(3): 645-658, (2018) (TMM Multimedia Prize Paper Award 2019) PDF
-
Xinchen Liu, Wu Liu, Huadong Ma, Shuangqun Li: A Progressive Vehicle Search System for Video Surveillance Networks. BigMM 2018: 1-7
-
Wenhui Gao, Xinchen Liu, Huadong Ma, Yanan Li, Liang Liu: MMH: Multi-Modal Hash for Instant Mobile Video Search. MIPR 2018: 57-62
2017
- Wu Liu, Xinchen Liu, Huadong Ma, Peng Cheng: Beyond Human-level License Plate Super-resolution with Progressive Vehicle Search and Domain Priori GAN. ACM Multimedia 2017: 1618-1626 PDF
2016
-
Shuangqun Li, Xinchen Liu, Wu Liu, Huadong Ma, Haitao Zhang: A discriminative null space based deep learning approach for person re-identification. CCIS 2016: 480-484
-
Xinchen Liu, Wu Liu, Tao Mei, Huadong Ma: A Deep Learning-Based Approach to Progressive Vehicle Re-identification for Urban Surveillance. ECCV (2) 2016: 869-884 PDF
-
Xinchen Liu, Wu Liu, Huadong Ma, Huiyuan Fu: Large-scale vehicle re-identification in urban surveillance videos. ICME 2016: 1-6 (Best Student Paper Award) PDF
Before 2015
- Xinchen Liu, Huadong Ma, Huiyuan Fu, Mo Zhou: Vehicle Retrieval and Trajectory Inference in Urban Traffic Surveillance Scene. ICDSC 2014: 26:1-26:6
Talks
December, 2024, China Conference on Artificial Intelligence (2024中国人工智能大会), 自然语言处理专题论坛, “人工智能基础模型走向多模态与产业落地” (In Chinese).
December, 2023, The 19th Young Scientists Conference of the Chinese Society of Image and Graphics (第19届中国图象图形学学会青年科学家会议), 优博论坛, “大规模自然场景步态识别初探” (In Chinese).
August, 2022, CCIG 2022 Young Scholar Panel (2022中国图象图形学大会,青年学者论坛), “Gait Recognition from 2D to 3D”. SLIDES
June, 2020, NCIG 2020 Outstanding Doctor and Young Scholar Panel (2020全国图象图形学学术会议,优秀博士与青年学者论坛), “Large-scale Vehicle Search in Smart City (智慧城市中的车辆搜索)” (In Chinese). SLIDES
Activities
Area Chair, ICME 2022/2024
Local Session Chair, ACM Multimedia 2021
Proceedings Co-Chair, ACM Multimedia Asia 2021
Co-chair, HUMA Workshop at ACM Multimedia 2020~2024
Journal Reviewer: IEEE TPAMI, IEEE TMM, IEEE TIP, IEEE TCSVT, IEEE TITS, IEEE TMC, ACM TOMM, ACM TIST, IoTJ, etc.
Conference Reviewer: CVPR, ACM MM, ICCV, ECCV, SIGIR, AAAI, ICME, ICASSP, ICIP, etc.
Membership: CCF/CSIG Senior Member, IEEE/ACM Member.
Awards and Honors
Chinese Association for Artificial Intelligence Wu Wenjun Artificial Intelligence Science and Technology Award, 2024, Special Prize for Technology Progress Award (2024年度中国人工智能学会吴文俊人工智能科技奖,科技进步特等奖 (3/15) )
ChinaMM Multimedia Industrial Innovative Technology Award, 2023, for the project “Key Technology on Multi-modal Human Analysis”
IEEE CAS MSA-TC Best Paper Award - Honorable Mention, 2022, for the paper “Part-level Action Parsing via a Pose-guided Coarse-to-Fine Framework”
ICCV 2021 DeeperAction Challenge, Track 3 Kinetics-TPS Challenge on Part-level Action Parsing, 2nd Award
IEEE CAS MSA-TC Best Paper Award - Honorable Mention, 2021, for the paper “TraND: Transferable Neighborhood Discovery for Unsupervised Cross-domain Gait Recognition”
Outstanding Doctoral Dissertation Award of China Society of Image and Graphics, 2019, for my Ph. D. thesis “Research on Key Techniques of Vehicle Search in Urban Video Surveillance Networks”
IEEE TMM Multimedia Prize Paper Award, 2019, for the paper “PROVID: Progressive and Multimodal Vehicle Reidentification for Large-Scale Urban Surveillance”
ICME 2019, 2021, Outstanding Reviewer Award
CVPR 2019 LIP Challenge, Track 3 Multi-Person Human Parsing, 2nd Award
CVPR 2018 LIP Challenge, Track 1 Single-Person Human Parsing, 2nd Award
IEEE ICME Best Student Paper Award, 2016, for the paper “Large-scale vehicle re-identification in urban surveillance videos”
Research
HOIGen-1M: A Large-scale Dataset for Human-Object Interaction Video Generation (More Details)
Text-to-video (T2V) generation has made tremendous progress in generating complicated scenes based on texts. However, human-object interaction (HOI) often cannot be precisely generated by current T2V models due to the lack of large-scale videos with accurate captions for HOI. To address this issue, we introduce HOIGen-1M, the first large-scale dataset for HOI Generation, consisting of over one million high-quality videos collected from diverse sources. In particular, to guarantee the high quality of videos, we first design an efficient framework to automatically curate HOI videos using the powerful multimodal large language models (MLLMs), and then the videos are further cleaned by human annotators. Moreover, to obtain accurate textual captions for HOI videos, we design a novel video description method based on a Mixture-of-Multimodal-Experts (MoME) strategy that not only generates expressive captions but also eliminates the hallucination by individual MLLM. Furthermore, due to the lack of an evaluation framework for generated HOI videos, we propose two new metrics to assess the quality of generated videos in a coarse-to-fine manner. Extensive experiments reveal that current T2V models struggle to generate high-quality HOI videos and confirm that our HOIGen-1M dataset is instrumental for improving HOI video generation.

Gait Recognition in the Wild with dense 3D Representations (More Details)
Existing studies for gait recognition are dominated by 2D representations like the silhouette or skeleton of the human body in constrained scenes. However, humans live and walk in unconstrained 3D space, so projecting the 3D human body onto the 2D plane will discard a lot of crucial information like the viewpoint, shape, and dynamics for gait recognition. Therefore, this paper aims to explore dense 3D representations for gait recognition in the wild, which is a practical yet neglected problem. In particular, we propose a novel framework to explore the 3D Skinned Multi-Person Linear (SMPL) model of the human body for gait recognition, named SMPLGait. Our framework has two elaborately designed branches, of which one extracts appearance features from silhouettes, and the other learns knowledge of 3D viewpoints and shapes from the 3D SMPL model. With the learned 3D knowledge, the appearance features from arbitrary viewpoints can be normalized in the latent space to overcome the extreme viewpoint changes in the wild scenes. In addition, due to the lack of suitable datasets, we build the first large-scale 3D representation-based gait recognition dataset, named Gait3D. It contains 4,000 subjects and over 25,000 sequences extracted from 39 cameras in an unconstrained indoor scene. More importantly, it provides 3D SMPL models recovered from video frames, which can provide dense 3D information of body shape, viewpoint, and dynamics. Furthermore, it also provides 2D silhouettes and keypoints that can be explored for gait recognition using multi-modal data. Based on Gait3D, we comprehensively compare our method with existing gait recognition approaches, which reflects the superior performance of our framework and the potential of 3D representations for gait recognition in the wild.
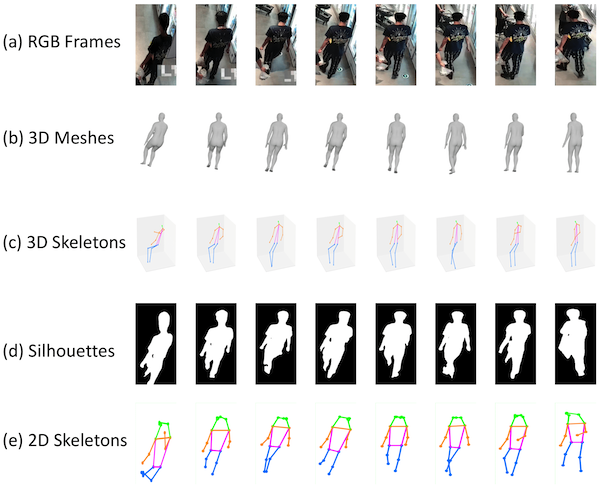
Progressive Vehicle Search in Larve-scale Surveillance Networks (More Details)
Compared with person re-identification, which has concentrated attention, vehicle re-identification is an important yet frontier problem in video surveillance and has been neglected by the multimedia and vision communities. Since most existing approaches mainly consider the general vehicle appearance for re-identification while overlooking the distinct vehicle identifier, such as the license number plate, they attain suboptimal performance. In this work, we propose PROVID, a PROgressive Vehicle re-IDentification framework based on deep neural networks. In particular, our framework not only utilizes the multi-modality data in large-scale video surveillance, such as visual features, license plates, camera locations, and contextual information, but also considers vehicle re-identification in two progressive procedures: coarse-to-fine search in the feature domain, and near-to-distant search in the physical space. Furthermore, to evaluate our progressive search framework and facilitate related research, we construct the VeRi dataset, which is the most comprehensive dataset from real-world surveillance videos. It not only provides large numbers of vehicles with varied labels and sufficient cross-camera recurrences but also contains license number plates and contextual information. Extensive experiments on the VeRi dataset demonstrate both the accuracy and efficiency of our progressive vehicle re-identification framework.

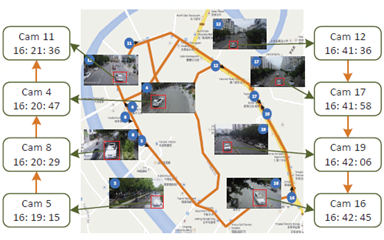
Multi-grained Vehicle Parsing from Images(More Details)
We present a novel large-scale dataset, Multi-grained Vehicle Parsing (MVP), for semantic analysis of vehicles in the wild, which has several featured properties. First of all, the MVP contains 24,000 vehicle images captured in read-world surveillance scenes, which makes it more scalable than existing datasets. Moreover, for different requirements, we annotate the vehicle images with pixel-level part masks in two granularities, i.e., the coarse annotations of ten classes and the fine annotations of 59 classes. The former can be applied to object-level applications such as vehicle Re-Id, fine-grained classification, and pose estimation, while the latter can be explored for high-quality image generation and content manipulation. Furthermore, the images reflect the complexity of real surveillance scenes, such as different viewpoints, illumination conditions, backgrounds, etc. In addition, the vehicles have diverse countries, types, brands, models, and colors, which makes the dataset more diverse and challenging. A codebase for person and vehicle parsing can be found HERE.
Fine-grained Human Parsing in Images
This paper focuses on fine-grained human parsing in images. This is a very challenging task due to the diverse person’s appearance, semantic ambiguity of different body parts and clothing, and extremely small parsing targets. Although existing approaches can achieve significant improvement through pyramid feature learning, multi-level supervision, and joint learning with pose estimation, human parsing is still far from being solved. Different from existing approaches, we propose a Braiding Network, named BraidNet, to learn complementary semantics and details for fine-grained human parsing. The BraidNet contains a two-stream braid-like architecture. The first stream is a semantic abstracting net with a deep yet narrow structure which can learn semantic knowledge by a hierarchy of fully convolution layers to overcome the challenges of diverse person appearance. To capture low-level details of small targets, the detail-preserving net is designed to exploit a shallow yet wide network without down-sampling, which can retain sufficient local structures for small objects. Moreover, we design a group of braiding modules across the two sub-nets, by which complementary information can be exchanged during end-to-end training. Besides, at the end of BraidNet, a Pairwise Hard Region Embedding strategy is proposed to eliminate the semantic ambiguity of different body parts and clothing. Extensive experiments show that the proposed BraidNet achieves better performance than the state-of-the-art methods for fine-grained human parsing.
Try Human Parsing Online API at JD Neuhub.


Social Relation Recognition in Videos
Discovering social relations, e.g., kinship, friendship, etc., from visual content can make machines better interpret the behaviors and emotions of human beings. Existing studies mainly focus on recognizing social relations from still images while neglecting another important media—video. On the one hand, the actions and storylines in videos provide more important cues for social relation recognition. On the other hand, the key persons may appear at arbitrary spatial-temporal locations, even not in the same image from beginning to end. To overcome these challenges, we propose a Multi-scale Spatial-Temporal Reasoning (MSTR) framework to recognize social relations from videos. For the spatial representation, we not only adopt a temporal segment network to learn global action and scene information but also design a Triple Graphs model to capture visual relations between persons and objects. For the temporal domain, we propose a Pyramid Graph Convolutional Network to perform temporal reasoning with multi-scale receptive fields, which can obtain both long-term and short-term storylines in videos. By this means, MSTR can comprehensively explore the multi-scale actions and storylines in spatial-temporal dimensions for social relation reasoning in videos. Extensive experiments on a new large-scale Video Social Relation dataset demonstrate the effectiveness of the proposed framework. The dataset can be downloaded from BaiduPan (~57GB, download code: jzei).


Last Update: July, 2025